Основы работы в R
2024-02-10
Установка
Для работы потребуется скачать и установить две программы:
Обе программы бесплатны и работают на Windows, MacOS или Linux1.
Кроме того, большинство возможностей R становятся доступны только после загрузки и подключения дополнений — пакетов. Это осуществляется командами из самой программы и требует только наличия подключения к интернету, поэтому ничего специально искать, скачивать и устанавливать не надо.
Работа в “чистом” R
После установки R на рабочем столе или в стартовом меню появляется доступ к стандартному графическому интерфейсу — то есть к программе, через которую мы взаимодействуем с R. Но в реальной работе обычно используют RStudio — улучшенный вариант графического интерфейса со множеством дополнительных возможностей, упрощающих работу.
Рассмотрим по очереди, как устроены эти программы. Графический интерфейс “чистого” R не вызывает особого восхищения:

Версия для Windows. Остальные отличаются не сильно.
Впрочем, для работы ничего из элементов интерфейса и не понадобится: всё управление будет осуществляться через команды, вводимые с клавиатуры. И сами команды, и результаты их выполнения будут отображаться в окне консоли (“R Console”). Результаты можно сразу копировать и вставлять в Word / Excel, однако работать с такими данными будет крайне неудобно из-за сломанного форматирования. Нормальные способы извлечения данных будут рассмотрены далее.
Графики, диаграммы и другие изображения появляются в новом окне (“R Graphics”):

Это окно можно раскрыть на полный экран — правда, изображение тогда перестроится, и его пропорции могут исказиться. Щелчком правой кнопки мыши по изображению можно скопировать его “как растровый файл” и, вставив в любой графический редактор (Paint, Gimp, и т.п.), Word или PowerPoint, сохранить в предпочитаемом формате. Это самый простой и быстрый способ вытащить из “чистого” R результаты анализа.
Интерфейс RSudio значительно сложнее и перегружен дополнительными функциями. Поэтому для начала рекомендуем настроить ему внешний вид так, чтобы он напоминал стандартный графический интерфейс R. Окно Rstudio по умолчанию состоит из 4 панелей, каждую из которых можно раскрывать/скрывать, как обычные окна в Windows. Всё, что требуется, — раскрыть левую нижнюю панель (консоль) и правую нижнюю панель (графики или справка). О полноценной работе с RStudio будет сказано далее.

RStudio, настроенный под классический интерфейс R
Основы работы в консоли
R:
Хранит в себе различные объекты: таблицы с данными, ряды чисел, массивы с текстом, и т.д.
Осуществляет с этими объектами разные операции с помощью встроенных (или создаваемых нами) функций.
Поэтому типичная команда в R выглядит так:
> функция(объект)
То есть указывает, какую функцию и над каким объектом применить. Функция обязательно дополняется скобками, в которых указывается объект и задаются параметры. Даже если ничего указывать не требуется, нужно поставить пустые скобки.
Рассмотрим основные варианты команд:
> объект — выводит содержимое объекта
В R встроено несколько демонстрационных баз данных. Используя их,
можно сразу изучать возможности программы, не загружая собственные
данные (что является достаточно трудоёмким процессом). В следующих
примерах используется база данных iris2. Чтобы посмотреть на
неё, достаточно ввести название объекта: iris.
> функция() — запускает функцию со стандартными
настройками. Например, data() выведет в отдельном окне
список всех встроенных баз данных наподобие iris.
> функция(объект) — проводит операцию над конкретным
объектом со стандартными настройками. Например, следующая команда
выводит для каждой переменной из iris несколько полезных параметров
описательной статистики (среднее, медиану, минимальное и максимальное
значение, а также 1 и 3 квартили; для последней переменной — число
ирисов каждого вида):
summary(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median :5.800 Median :3.000 Median :4.350 Median :1.300
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Species
setosa :50
versicolor:50
virginica :50
Выше мы использовали команду iris, чтобы посмотреть на
эту базу данных. Но в результате выводится вся таблица целиком. Это
может быть неудобно, когда наблюдений (строк таблицы) больше нескольких
десятков. Функции head() и tail() позволяют
вывести лишь несколько первых или последних строк:
head(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosatail(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species
145 6.7 3.3 5.7 2.5 virginica
146 6.7 3.0 5.2 2.3 virginica
147 6.3 2.5 5.0 1.9 virginica
148 6.5 3.0 5.2 2.0 virginica
149 6.2 3.4 5.4 2.3 virginica
150 5.9 3.0 5.1 1.8 virginicaА функция View() позволяет вывести таблицу в отдельном
окне в виде, напоминающем таблицу Excel. Обратите внимание: название
этой функции начинается с заглавной буквы V. Регистр букв в командах
имеет значение. Поэтому команда view(iris) не
сработает.
> функция(объект, параметр1 = ..., параметр2 = ..., и т.д.)
— проводит операцию над конкретным объектом, указывая ряд
параметров.
Параметры настраивают работу функции нужным образом. Например, вывод
команды summary(iris) можно сделать более лаконичным,
уменьшив число знаков после запятой следующим образом:
summary(iris, digits = 2) Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.3 Min. :2.0 Min. :1.0 Min. :0.1 setosa :50
1st Qu.:5.1 1st Qu.:2.8 1st Qu.:1.6 1st Qu.:0.3 versicolor:50
Median :5.8 Median :3.0 Median :4.3 Median :1.3 virginica :50
Mean :5.8 Mean :3.1 Mean :3.8 Mean :1.2
3rd Qu.:6.4 3rd Qu.:3.3 3rd Qu.:5.1 3rd Qu.:1.8
Max. :7.9 Max. :4.4 Max. :6.9 Max. :2.5 А для функции head() можно указать, сколько именно строк
таблицы она будет выводить:
head(iris, n = 10) Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosaЕсли вводить только значение параметра, не указывая его имя, то функция попытается “догадаться” сама, исходя из стандартного порядка её параметров, введённого значения, и т.п. Хоть это может породить множество ошибок, но часто оказывается удобным. Например, следующие три команды равнозначны:
head(x = iris, n = 10)
head(iris, n = 10)
head(iris, 10)Да, получается, что имя объекта для этой функции — это значение параметра x.
Помощь и справочная информация
Какие параметры можно указать для каждой функции, и какие значения
они могут принимать? На этот и многие другие вопросы отвечает справочная
функция help() или её сокращенный вариант: знак
? перед названием функции:
?headВ разделе Usage указаны основные способы вызова функции и её
ключевые параметры, которые обязательно должны быть заданы, чтобы
функция сработала. При этом многие параметры имеют стандартное значение,
которое используется автоматически, если не указывать иное. Например, в
справке по функции head() можно найти основной способ её
вызова:
head(x, n = 6, ...)Это значит, что если не указать напрямую параметр n, то функция выводит 6 первых строк таблицы3. Подробнее про все параметры можно прочесть в разделе Arguments.
Помимо функций справку можно получить по базам данных
(?iris) и пакетам (например,
help(package = "base") выведет все функции и встроенные
объекты, входящие в основной пакет R). Существует дополнительный тип
справочной информации — “виньетки”, написанные в свободной форме и более
дружественным языком. Как правило, каждый устанавливаемый пакет включает
минимум по одной из них. Посмотреть полный список можно командой
vignette() без параметров.
Наконец, огромное количество учебных и справочных статей, ответов на вопросы и руководств можно найти в интернете, стандартным поиском. Практически все проблемы, с которыми сталкиваются начинающие (и далеко не только) пользователи R, были многократно решены и разобраны.
Новые объекты
Результаты выполнения команды можно сохранить в виде нового объекта
сочетанием символов <-4
имя_нового_объекта <- команда
Название для нового объекта можно придумать произвольное, лишь бы оно не совпадало с существующими объектами и функциями.
Добавление собственных данных
По мнению многих статистиков, добавление, “очистка” и подготовка данных к анализу тратят значительно больше времени и сил, чем сам анализ. Подробнее способы импорта и последующей модификации данных будут рассмотрены позже. Для начала приведём лишь самый простой способ добавления данных из Excel (для Windows). Подготовьте данные так, чтобы измерения каждой переменной располагались в столбцах, и в верхней строке содержались названия переменных. Выделите нужный диапазон ячеек, скопируйте, и выполните в R следующую команду (слово “clipboard” менять не нужно):
имя_нового_объекта <- read.delim2("clipboard")Полезные функции
ls() |
выводит список всех объектов, созданных пользователем |
str(объект) |
важная информация об объекте; например, число и тип переменных в таблице |
rm(объект) |
удалить объект |
rm(list = ls()) |
удалить все объекты |
getwd() |
узнать рабочую директорию – т.е. место на компьютере, откуда R читает и куда сохраняет все файлы |
setwd("путь до папки") |
сделать указанную папку новой рабочей директорией |
c(объект1, объект2, ...) |
объединить несколько одинаковых объектов |
Последняя функция создаёт вектор, последовательность из однотипных значений. Векторы удобно “сохранять” в виде новых объектов:
a <- c(4, 8, 15, 16, 23, 42)
b <- c("Здравствуйте", "спасибо", "до свидания!")
# Значениям вектора можно давать названия для наглядности:
po_statistike <- c(Девчонок = 10, Ребят = 9)a[1] 4 8 15 16 23 42b[1] "Здравствуйте" "спасибо" "до свидания!"po_statistikeДевчонок Ребят
10 9 Полезные мелочи
- За редкими исключениями, пробелы в тексте команды не имеют значения. Следующие команды равнозначны:
summary(iris,digits=2)
summary(iris, digits = 2)
summary ( iris , digits = 2 )Десятичные дроби разделяются точкой, а не запятой.
Любой текст, не являющийся именем объекта, функции или параметра, нужно окружать в ‘одинарные’ или “двойные” кавычки.
Клавиша Tab достраивает название функции, объекта или даже пути к файлу, которые вы начали вводить. Попробуйте нажать её, предварительно введя
summилиsummary(ir. Если существует несколько вариантов достроить команду, то двойное нажатие на Tab покажет их.Стрелка вверх выводит предыдущие выполненные команды. Можно отредактировать и использовать повторно.
В сложных командах легко ошибиться со всеми необходимыми скобками. Если после ввода ничего не происходит, а на новой строке появляется +, то это верный признак, что пропущена закрывающая скобка. Можно сразу поставить её и ещё раз нажать Enter.
Скрипты
Такие операции, как построение графиков, требуют большого числа команд, содержащих множество параметров. Удобно сохранять последовательности команд отдельным текстовым файлом с расширением .R — скриптом. Так с ними гораздо проще работать и при необходимости менять.
В RStudio работа со скриптами встроена по умолчанию. Если понадобится
использовать их в “чистом” R, то можно использовать команду
source("путь/до/скрипта"), но самый простой способ —
скопировать все команды сразу и вставить в командную строку консоли.
Попробуйте сделать так со следующим небольшим скриптом:
# Чтобы вносить в скрипты комментарии, ставьте перед ними знак #. Эти строки можно спокойно
# копировать вместе с остальными командами, не боясь вызвать ошибку.
# Следующий скрипт выводит гистограммы распределения четырёх переменных таблицы iris в
# приятной для глаз форме.
oldpar <- par ( mfrow = c(2,2) )
plotname <- c("Длина чашелистиков", "Ширина чашелистиков", "Длина лепестков", "Ширина лепестков")
for (i in 1:4) {
hist (
iris [[ i ]],
breaks = 12,
freq = FALSE,
col = i+2,
main = plotname[i],
xlab = "Сантиметры",
ylab = "Частота"
)
rug ( jitter ( iris [[ i ]] ) )
lines ( density (iris [[ i ]] ), col = i+1, lwd = 2 )
box()
}
par (oldpar)
rm (plotname, oldpar)Пакеты
Многие полезные функции становятся доступны при подключении к R
дополнений — пакетов. В них могут также входить
дополнительные тренировочные базы данных, расширения для программы, и
пр. Некоторые пакеты поставляются вместе с R, но большинство нужно
загружать и устанавливать самостоятельно. Это производится командой
install.packages("имя_пакета"), при этом может
потребоваться выбрать зеркало для скачивания — выбирайте любое.
Например, установка одного из самых востребованных пакетов,
Tidyverse:
install.packages("tidyverse")Устанавливать любой пакет нужно только один раз. Однако при каждом
запуске R требующиеся пакеты нужно подключать командами
library(), каждый по отдельности. В качестве примера:
library(MASS)
library(car)
library(tidyverse) # обратите внимание: в данном случае без кавычек
library(magrittr)
library(patchwork)
...Существуют способы настроить R так, чтобы нужные пакеты подключались при запуске программы автоматически. Но правилом хорошего тона при написании скриптов будет оставлять эти команды в самом начале, чтобы потенциальный пользователь (в том числе сам автор скрипта через несколько лет) мог сразу с ними ознакомиться, заранее установить недостающие пакеты и предусмотреть возможные ошибки совместимости.
Функции можно вызывать и без подключения пакета командой
пакет::функция(). Это может быть также полезно, если
несколько запущенных пакетов содержат одноименные функции. Например,
stats::filter() и dplyr::filter().
Встроенные базы данных
Демонстрационные таблицы вроде iris встроены в R для
тренировки работы с различными функциями и разновидностями
статистического анализа. Как правило, это реальные данные из научных
работ или популярных учебников по статистике. Многие пакеты, расширяющие
функционал R, также содержат дополнительные базы данных — они становятся
доступны при подключении пакета. Далее перечислено несколько популярных
примеров, посмотреть на весь список можно командой
data().
mtcars
Изучение зависимости потребления топлива (mpg — miles per gallon, миль/галлон) 32 автомобилей от 10 особенностей конструкции. Переменные по сути разных типов, но все представлены или закодированы числовыми данными.
Зачем: преобразование данных в факторы и упорядоченные факторы, регрессионный анализ, множественные регрессии, построение простых или сложных графиков, отражающих взаимосвязь переменных, и вычленение групп.
mpg
Аналог mtcars из Tidyverse. Часто встречается в различных примерах в интернете. Вместо одной переменной mpg сразу две переменные, отражающие экономичность автомобиля: cty (в городе) и hwy (на трассе).
trees
Объем, высота и
обхватдиаметр 31 дерева.Зачем: диаграммы рассеяния, корреляции и регрессионный анализ.
PlantGrowth и ToothGrowth
Влияние различных экспериментальных факторов на урожай растений или длину зубов морских свинок.
Зачем: изучение однофакторного и двухфакторного дисперсионного анализа.
state.x77
Связь числа убийств в каждом штате США с численностью населения, образованностью, достатком и другими переменными.
Зачем: множественные регрессии, дисперсионный анализ с ковариацией, многомерный анализ: факторный и кластерный анализ.
co2
468 измерений концентрации CO2 в атмосфере с 1959 по 1997 годы.
Зачем: анализ временных рядов.
Работа в RStudio
Программа RStudio значительно упрощает многие аспекты работы. Для любого пользователя, уже знакомого с R, её преимущества будут очевидны:
- встроенный редактор скриптов
- подсказки имён объектов и функций, появляющиеся во время набора
- умное добавление при печати парных элементов: кавычек и скобочек
- удобное управление объектами и историей — забудьте про
ls()иrm() - удобное управление папками и файлами — забудьте про
setwd()иgetwd() - наглядное управление установленными пакетами
- расширенные варианты экспорта графиков
- полезные сочетания клавиш
- и многое другое, что становится актуально в ходе дальнейшего ознакомления с R.
Окно RStudio разделено на четыре панели, каждую можно скрывать, раскрывать на всю колонку или раскрывать на весь экран. Содержимое можно настроить под свой вкус, но исходно оно распределено примерно так:
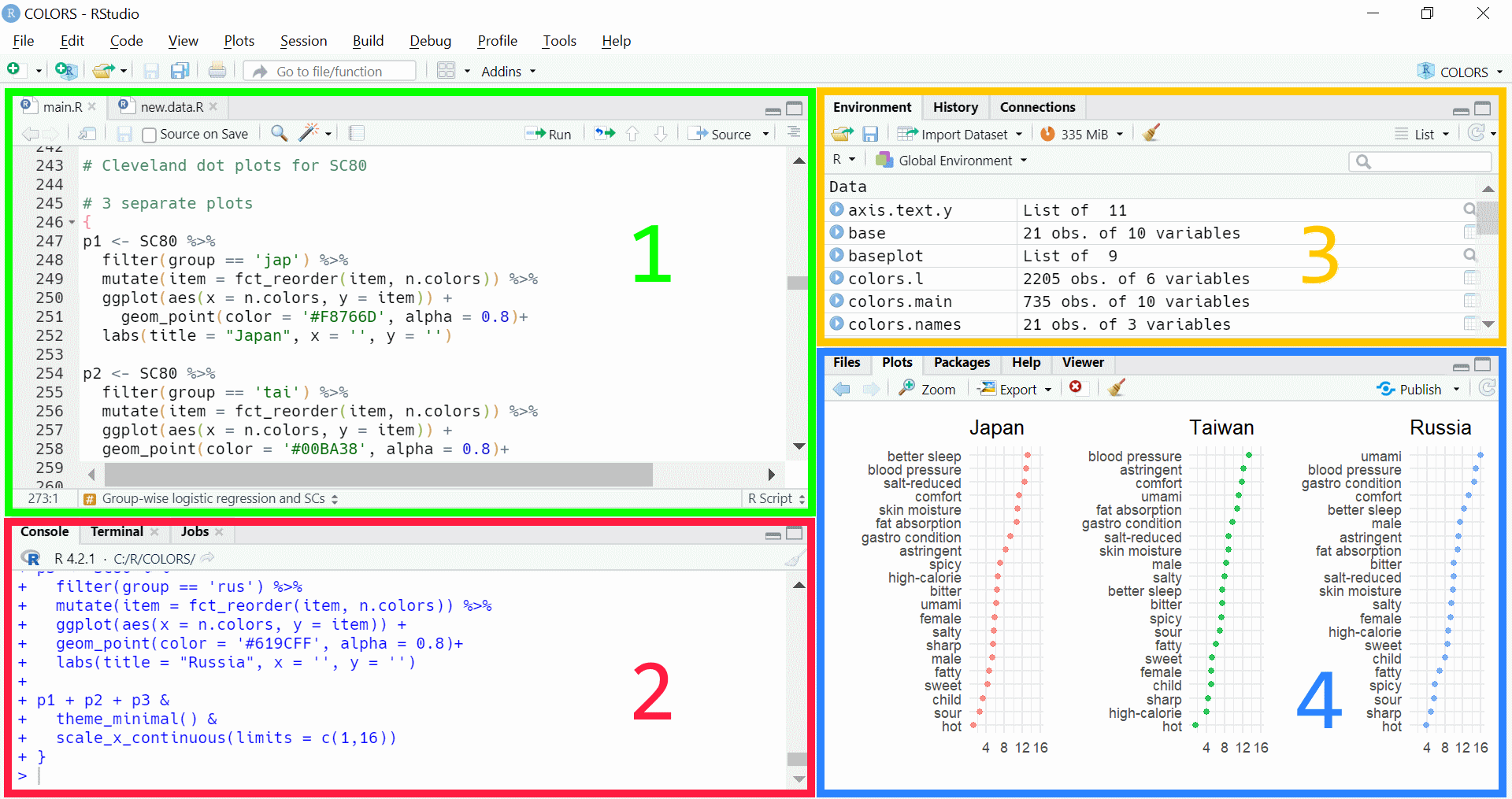
1 — редактор скриптов, 2 — консоль, 3 — список объектов и история введенных команд, 4 — графики, справка, список файлов и список установленных пакетов
Консоль (панель 2) работает точно так же, как в стандартном графическом интерфейсе. Но основным рабочим пространством в RStudio становится редактор скриптов (панель 1). Это текстовый файл, в который можно вносить любые последовательности команд и исполнять их по отдельности, или все сразу. Чтобы выполнить весь скрипт, нужно нажать на кнопку Source в верхней правой части панели. Гораздо чаще выполняют отдельные команды — для этого нужно щелкнуть на команду (или выделить необходимый участок из нескольких команд) и нажать сочетание Ctrl+Enter. Результат будет выведен в консоли или в панели 4 (графики или справка).
Длинные команды можно разделять на множество строк для удобства и наглядности (как в примере выше). Рекомендуем также комментировать каждый набор команд (комментарий начинается с символа #), описывая их предназначение, и разделять комментариями код на разделы — это позволит впоследствии легко ориентироваться в своих собственных скриптах.
С помощью списка объектов (панель 3) можно быстро
просматривать созданные объекты и следить за их состоянием. Таблицы
данных открываются в виде новых вкладок панели 1. Панель 4 содержит в
виде вкладок список файлов рабочего каталога и список
установленных пакетов (можно включать/выключать их без команды
library()), а также вывод для графиков и справок. Программа
помнит построенные графики и открытые страницы справки, можно
возвращаться к ним стрелками в верхней части панели.
Сохранение изображений
Извлекать построенные графики из RStudio гораздо удобнее, чем из “чистого” R: помимо копирования изображения, кнопкой Export его можно сразу сохранить в виде растрового файла (png, jpg) или pdf без помощи сторонних программ.
Растровый файл — “обыкновенное” изображение, которое нельзя сильно увеличивать, иначе качество ухудшается. Доступны форматы png, jpg, tiff, bmp и другие. Если вы не разбираетесь в разнице между ними, рекомендуем по умолчанию выбирать png.
Файл pdf — векторный, т.е. изображение более чёткое, и его можно масштабировать любым образом. Цена — увеличение размера файла. При сохранении файла обязательно поставьте галочку перед строкой “Use cairo_pdf device”, чтобы избежать проблем с русскими надписями в изображении.
Полезные сочетания клавиш в RStudio
| Ctrl+Enter | Выполнить команды на выбранных строках |
| Alt+минус | Вставить оператор создания объекта <- |
| Ctrl+Shift+M | Вставить оператор конвейера %>% (см. далее) |
| Ctrl+Shift+C | “Закомментировать” выделенные строки, т.е. поставить перед каждой символ # |
| Ctrl+Shift+1 | Раскрыть панель 1 целиком на всё окно RStudio |
| F1 | Открыть справку по функции или объекту, на который наведён курсор |
Tипы данных и виды объектов
Объекты R хранят данные конкретных типов: текстовые (всегда
вводятся/выводятся в кавычках), логические (logical) и числовые
(numeric), которые в свою очередь могут быть целочисленными (integer)
или рациональными (double). Выяснить тип данных объекта может команда
str(). Для пользователя разница может быть не критичной, но
большинство функций требуют для нормальной работы конкретный тип данных:
посчитать среднее значение для последовательности из кусков текста у вас
не получится.
Логические данные могут принимать только два значения: TRUE (истина) или FALSE (ложь). Записываются они без кавычек, и можно сокращать до первых букв, T или F. Такие данные используются для ответа вида “да/нет” или “вкл/выкл” и часто применяются при установке параметров функций.
И отдельным типом данных является “пропущенное значение” — NA (без кавычек), которое в таблицах с экспериментальными данными стоит применять вместо пустых ячеек, когда результатов по каким-либо причинам нет.
Кратко рассмотрим основные виды объектов в R:
Таблица данных (data frame) — основной способ организации экспериментальных данных в R. Наиболее близко соответствует типичным таблицам в Excel. Каждый столбец в таблице может быть разного типа: один — текстовый, другой — числовой, и т.д. Обычно столбцы соответствуют измеряемым величинам (переменным), а строки — это отдельные наблюдения / измерения. Таблица iris как раз представляет собой data frame.
Первым этапом любого анализа данных будет импорт ваших результатов из внешних файлов (обычно таблиц Excel) в R и превращение их в data frame. К сожалению, эта процедура может быть крайне трудоёмкой и описана в отдельном разделе.
Tibble — для обычного пользователя это то же самое, что data frame, но выводится в консоли более информативно и удобно. Часть мета-пакета Tidyverse.
Вектор — последовательность значений одного типа:
ряд чисел, фрагменты текста, и т.д. Создаётся функцией c().
Если попробовать создать вектор из значений разного типа, они все
автоматически будут превращены в текстовые данные. Типичные примеры
использования векторов:
- один столбец data frame
- одна выборка измерений
- все значения переменной
- набор параметров одного объекта
- список таксонов
Список (list) — похож на вектор, но может содержать разные типы данных и даже разные объекты, включая таблицы и другие списки. Пользователи создают и используют списки редко, зато они часто являются результатом анализа, выполняемого функциями.
Матрица и массив — многомерные векторы. Похожи на таблицы, но в отличие от data frame в типичном анализе данных используются редко.
Фактор — текстовый вектор, но все его элементы могут принимать только ограниченный, заранее прописанный набор значений. Например, оценивая пол экспериментальных животных, мы можем получить только два5 результата: “самец” или “самка”. Аналогично, оценивая морфологию бактериальных клеток, мы можем сразу для себя решить, что будем классифицировать их как “кокки”, “палочки”, “спиральные” и “другое”. Оценивая наличие активности, мы указываем “+” или “-”. И так далее.
Числовой вектор можно легко превратить в фактор командой
factor(имя вектора).
Факторы усложняют жизнь пользователя, т.к. одни функции R предполагают использование текстовых векторов, другие — факторов. Иногда функция автоматически превращает один тип данных в другой, но чаще это может приводить к ошибкам.
Факторы могут также быть упорядоченными — когда можно
расставить уровни фактора по возрастанию (но без точной количественной
оценки). Скажем, визуально оценивать рост культуры на чашке Петри можно
терминами “отсутствует”, “слабый”, “средний”, “выраженный”. Можно
отображать интенсивность роста и рангами: “1”, “2”, “3”, “4”; или “+”,
“++”, “+++”, “++++”; и т.д. Для программы не имеет значения конкретное
текстовое содержание, главное — какой из четырёх упорядоченных уровней
фактора присвоен каждому изученному экспериментальному объекту. Получить
упорядоченный фактор из обычного или сразу из числового вектора можно
командой ordered().
Работа с таблицами
Кратко рассмотрим стандартные операции с таблицами: извлечение требуемых столбцов или строк. Более сложные операции, такие как модификация и добавление столбцов, преобразование таблиц и создание сводных таблиц, рассмотрены в разделе, посвященном диалекту Tidyverse.
Выбор столбцов = выбор переменных
Отдельный столбец можно извлечь, указав его номер в квадратных
скобках после имени таблицы. Несколько столбцов указываются вектором с
их номерами (функция c()). Можно и наоборот, убрать
ненужные столбцы, поставив перед их номером минус.
iris[1] Sepal.Length
1 5.1
2 4.9
3 4.7
4 4.6
...iris[c(1,3)] Sepal.Length Petal.Length
1 5.1 1.4
2 4.9 1.4
3 4.7 1.3
4 4.6 1.5
...iris[-5] Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.1 3.5 1.4 0.2
2 4.9 3.0 1.4 0.2
3 4.7 3.2 1.3 0.2
4 4.6 3.1 1.5 0.2
...Во всех этих случаях мы получаем новую, урезанную таблицу — опять data frame, даже если она состоит лишь из одного столбца. Но часто нам надо получить столбец именно в виде вектора, т.е. последовательности чисел. Для этого нужно использовать двойные квадратные скобки:
iris[[1]]5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...Альтернативный и, как правило, более удобный способ — выбор столбца по имени с помощью оператора ‘$’:
iris $ Sepal.Length 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...# обычно пишут без пробелов: iris$Sepal.LengthВыбор строк = фильтрация наблюдений
Обычно имеет смысл извлекать не отдельные строки, а несколько наблюдений, удовлетворяющих какому-то критерию. То есть, производить фильтрацию. Например, извлечь из таблицы iris измерения только для ирисов конкретного вида:
iris[iris$Species == 'versicolor' ,] Sepal.Length Sepal.Width Petal.Length Petal.Width Species
51 7.0 3.2 4.7 1.4 versicolor
52 6.4 3.2 4.5 1.5 versicolor
53 6.9 3.1 4.9 1.5 versicolor
54 5.5 2.3 4.0 1.3 versicolor
...Или выбрать все ирисы, у которых лепестки были длиннее 6 см:
iris[iris$Petal.Length > 6 ,] Sepal.Length Sepal.Width Petal.Length Petal.Width Species
106 7.6 3.0 6.6 2.1 virginica
108 7.3 2.9 6.3 1.8 virginica
110 7.2 3.6 6.1 2.5 virginica
118 7.7 3.8 6.7 2.2 virginica
119 7.7 2.6 6.9 2.3 virginica
123 7.7 2.8 6.7 2.0 virginica
131 7.4 2.8 6.1 1.9 virginica
132 7.9 3.8 6.4 2.0 virginica
136 7.7 3.0 6.1 2.3 virginicaОбратите внимание на запятую в конце каждой команды. В обоих случаях
применяется конструкция вида [ , ], где выражение перед
запятой определяет выбор строк, а после запятой — выбор столбцов.
Соответственно, указав и то, и другое, можно выбрать отдельную ячейку.
Если не указывать ничего, то будут взяты, соответственно, все строки или
(как в примерах выше) все столбцы.
Рассмотренные методы работы с таблицами применяются таким же образом для манипуляций с векторами, факторами и другими типами объектов.
Дополнение: стандартная графическая система
Один из самых популярных на данный момент способов построения разнообразных графиков в R — графическая система ggplot2, и далее в основном мы будем использовать именно её. Однако со стандартной графической системой R тоже нужно познакомиться, т.к. принципы управления ей характерны для большинства дополнительных графических функций, поставляемых тысячами специализированных пакетов. Рассмотрим кратко эти принципы. Полноценно ознакомиться с системой можно с помощью рекомендованных учебников6 или на многочисленных онлайн-ресурсах (например).
Все графические функции можно поделить на первичные,
строящие новый график (и стирающие всё, что было построено ранее), и
вторичные, добавляющие к уже существующему графику
дополнительные элементы. Впрочем, можно добавлять к существующему
изображению и график, построенный первичной функцией, если задать ей
параметр add = TRUE.
Некоторые первичные графические функции
plot() |
Универсальная графическая функция. Линейные графики и диаграммы рассеяния, либо подбирает более подходящую функцию из этой таблицы. |
hist() |
Гистограмма — отображение распределения переменной. |
barplot() |
Столбчатая диаграмма. |
boxplot() |
Ящики-с-усами, или “боксплоты”. |
stripchart() |
Все значения каждой переменной по категориям — удобнее боксплотов, когда измерений в пределах 10 – 20. |
dotchart() |
Точечная диаграмма Кливленда — соотношение числовой и качественной переменных. |




Чаще всего требуется построить зависимость одной количественной переменной от другой. За это отвечает функция plot(). Впрочем, она достаточно “умна”, чтобы при необходимости вызвать другую функцию. Например, если указать ей только одну переменную; или если одна из переменных факторная.
Есть два основных способа задать объекты для функции plot() и других графических функций:
- прямо указать данные для каждой оси:
plot(x = ..., y = ...) - “формульный” способ:
plot(y ~ x), напоминает логику записи алгебраических функций “y = f(x)”
Понимать формульный способ указания переменных полезно: многие продвинутые графические функции используют аналогичные, но более сложные формулы; кроме того, они же применяются при создании моделей в регрессионном анализе.
Для примера построим зависимость экономичности автомобилей (mpg) от объема двигателя (disp) из встроенной базы данных mtcars:
# Эти функции выводят одно и то же:
plot(mtcars$disp, mtcars$mpg) # название параметров "х" и "y" часто опускают
plot(mtcars$mpg ~ mtcars$disp) # формульный способ
plot(mgp ~ disp, data = mtcars) # упрощаем текст параметром data=
Параметр type= выбирает тип графика
| type= | Что рисует функция |
|---|---|
| p | точки (points) |
| l | линии (lines) |
| b | точки и линии (both) |
| c | как b, но пустоты вместо точек |
| o | точки поверх линий (over) |
| s | ступеньками снизу (steps) |
| S | ступеньками сверху (Steps) |
| h | вертикальные линии как в гистограмме (histogram) |
| n | ничего не рисует (none) |

Параметры для изменения оформления
main= |
заголовок |
sub= |
подзаголовок |
xlab= ylab= |
подписи осей |
xlim= ylim= |
диапазон осей, вектор из двух значений:
c(мин, макс) |
add=T |
добавляет этот график к существующему изображению |
Графические параметры для изменения рисуемых объектов
col= |
цвет: задаётся номером, словом (“green”), хэш-кодом (#00FF00) или RGB-кодом (rgb(0,255,255)) |
pch= |
символ для точек: 0–25, или любой символ в кавычках (см. рисунок) |
cex= |
размер символа: 1 = стандартный, 1.5 = на 50% больше, и т.д. |
lty= |
тип линии: 1–6, или название (см. рисунок) |
lwd= |
толщина линии: 1 = стандартная, 2 = в два раза толще, и т.д. |
bg= |
цвет фона самого графика или заливка геометрических объектов и символов 21–25 |

Также существуют производные параметры для настройки элементов
графика: col.main= указывает цвет заголовка,
cex.lab= — размер подписей к осям, и т.д. С полным списком
всех графических параметров можно ознакомиться с помощью
?par.
Легенда и добавление элементов
Добавить элементы на построенный график можно с помощью вторичных функций. Многие из них принимают те же параметры, рассмотренные выше.
lines() |
Достраивает линии. |
points() |
Достраивает точки. |
title() |
Параметры main=, sub=,
xlab=, ylab=, и другие. |
axis() |
Строит новые оси. Обратите внимание на параметры
side= и pos=. |
legend() |
Добавляет легенду. |
Легенда добавляется командой
legend(location= , legend= , ...). Параметр
location= указывает место для размещения легенды и
принимает значения вида “topleft”, “bottomright” и т.п. Альтернативно,
можно задать координаты x и y. Параметру
legend= (не путать с именем самой функции) нужно указать
текстовый вектор с подписями. Как правило, это либо названия переменных
— столбцов в таблице (colnames(iris)), либо уровни фактора
(levels(iris[[5]])). Можно задать текст и вручную, создав
вектор функцией с(). Обратите внимание: точки и/или линии
появятся в легенде только если явно задать параметр pch=
(точки) и lty= или lwd= (линии).
В некоторых дистрибутивах Linux R предустановлен по умолчанию.↩︎
У 150 ирисов трёх видов определяли длину и ширину “лепестков” и “чашелистиков”. В таблице первые 4 столбца содержат полученные измерения, 5 столбец – видовая принадлежность.↩︎
В оригинальной справке написано “n = 6L”. “6L” означает целочисленный тип данных, но для пользователя это не принципиально, поэтому для простоты мы изменили запись на “n = 6”.↩︎
В RStudio оператор
<-удобно вставлять сочетанием клавиш Alt+минус.↩︎вроде бы пока ещё↩︎
“R in Action”: глава 3, а также 6, 11, 16; Шипунов и др.: разделы 2.7.4–2.7.7 и приложение Г.15↩︎